Category: Technology
-
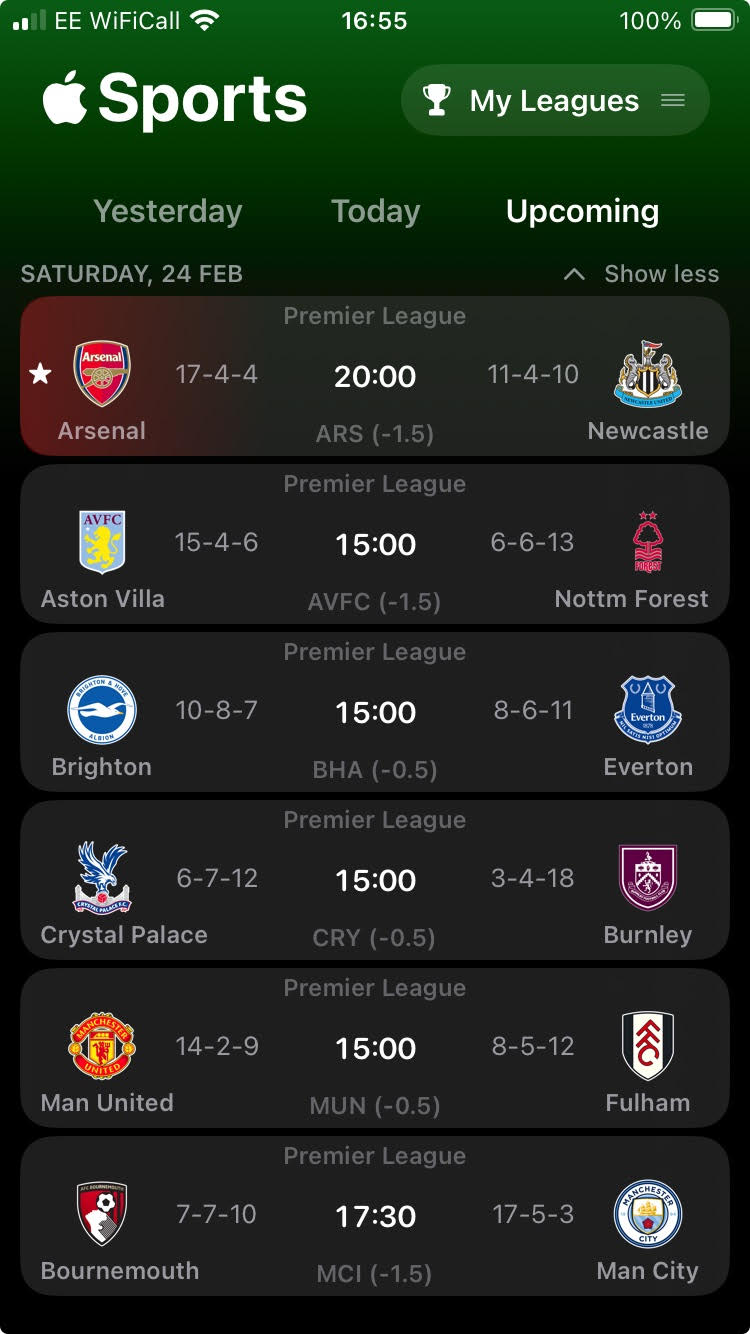
Apple’s Sports App
This week Apple launched a new app entirely devoted to sport. Apple Sports is initially available in the US, Canada and UK, and has a relatively small list of features. You basically pick which leagues you’re interested in, and which teams within those leagues you follow, and it’ll happily provide you with things like line-ups,…
-

Keychron K2
Like many people, I’ve been fascinated with the emergence/re-emergence of mechanical keyboards over the last few years. YouTube is full of videos of them, and there are endless comparisons of what different switches sound like. There’s also a whole industry of people building their own keyboards. The trouble is that it all seems so complicated.…
-

RSS Headline Display with Raspberry Pi Zero and Pimoroni Inky wHAT E-ink Display
Back in 2019 I was quite pleased when I built an e-ink display which would display the latest news headlines from a handful of news providers. My solution utilised those outlets’ Twitter feeds. But now it’s mid-2023 and Twitter in its old guise is no more. More importantly with respect to that previous project, it…
-
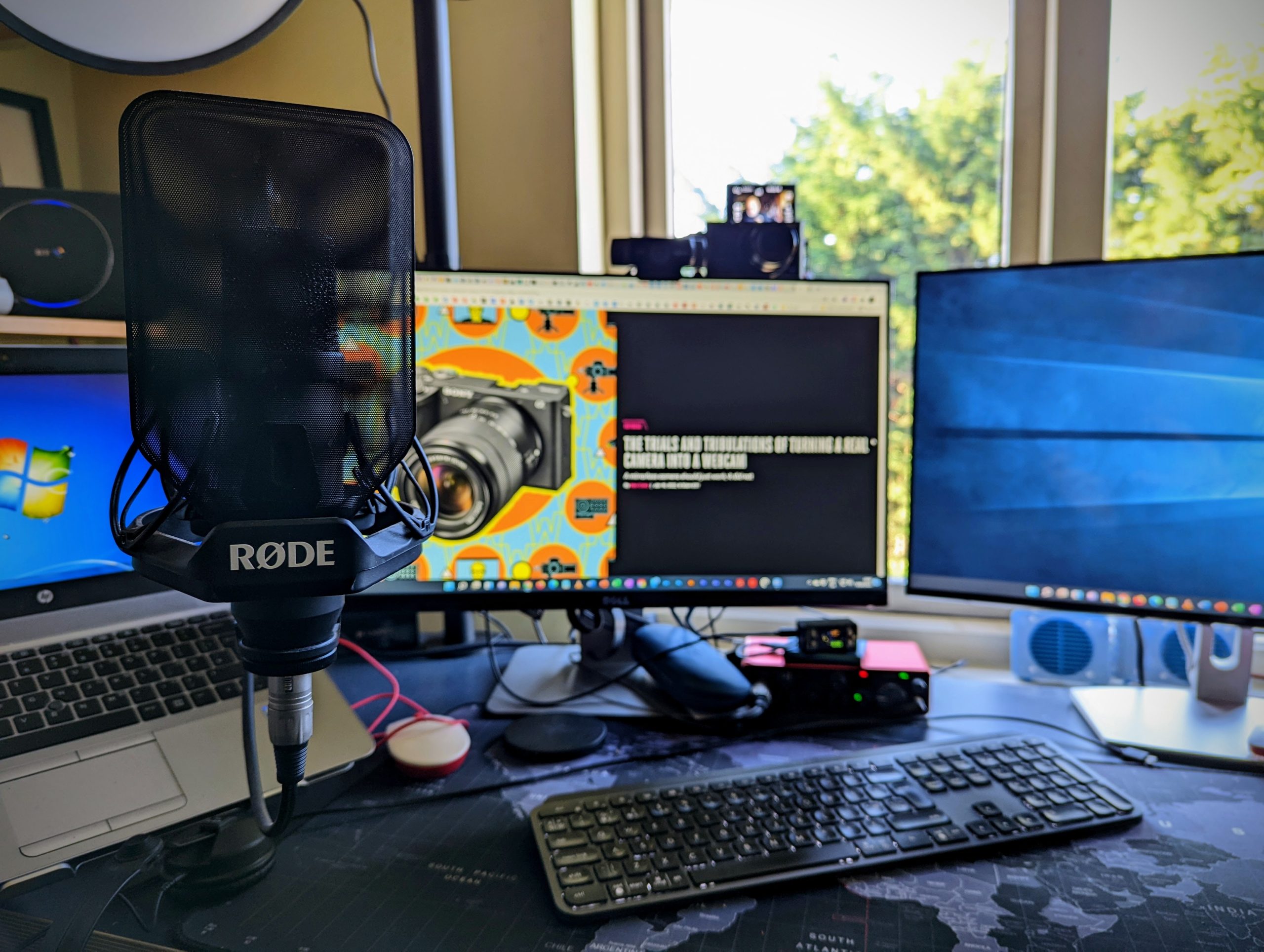
Upping Your WFH Video Game
This piece by Alex Cranz at The Verge really struck a chord with me. In the piece Alex writes about her trials and tribulations with trying to use her nice Sony mirrorless camera as a webcam, and generally having a good Working From Home video set-up. I’m 100% onboard with this. Fairly soon after lockdown…
-

Raspberry Pi Pico Solar System
The October 2021 issue of MagPi magazine featured Dymtri Panin’s Pico Solar System, and I fancied building one. The Raspberry Pi Pico is a tiny microcontroller board that costs a whopping £3.60 or so. It is powered by a microUSB socket and it can run bits of code that allow it to control things on…
-

Snow Crash by Neal Stephenson
Recently Facebook CEO Mark Zuckerberg spoke to Casey Newton of The Platformer, for both his newsletter and The Vergecast podcast. It was a wide ranging interview covering many of the hot-button topics of the day – not least Covid misinformation on Facebook’s platforms and what they were doing about it. But the interview kicked off…
-

Pimoroni Keybow Zoom Controller
Pimoroni makes a wonderful little package called the Keybow which comes in 3 key and 12 key options. It uses a Raspberry Pi Zero on top of which sit some LED keys (there are both clicky or quiet). You can then program the whole thing to allow you to use keyboard shortcuts to do various…
-

The Pros and Cons of YouTube Music – September 2020 Edition
I’ve been a user of Google Play Music for quite some time now – almost exclusively because they uniquely allow you to upload your own music (or other audio) to their servers. You could upload 50,000 tracks to the site. Why is this important? Maybe you have music that hasn’t been commercially released? Your friend’s…
-

Building A Computer
For something like 10-15 years now, my main computer has been a laptop. Most recently, a Dell XPS 2015 with an Intel i7-6700 processor, and which I upgraded to 32GB RAM at some point. But I always struggled with just a single 500GB M2 SSD, with video taking up too much space. Once you’ve got…
-
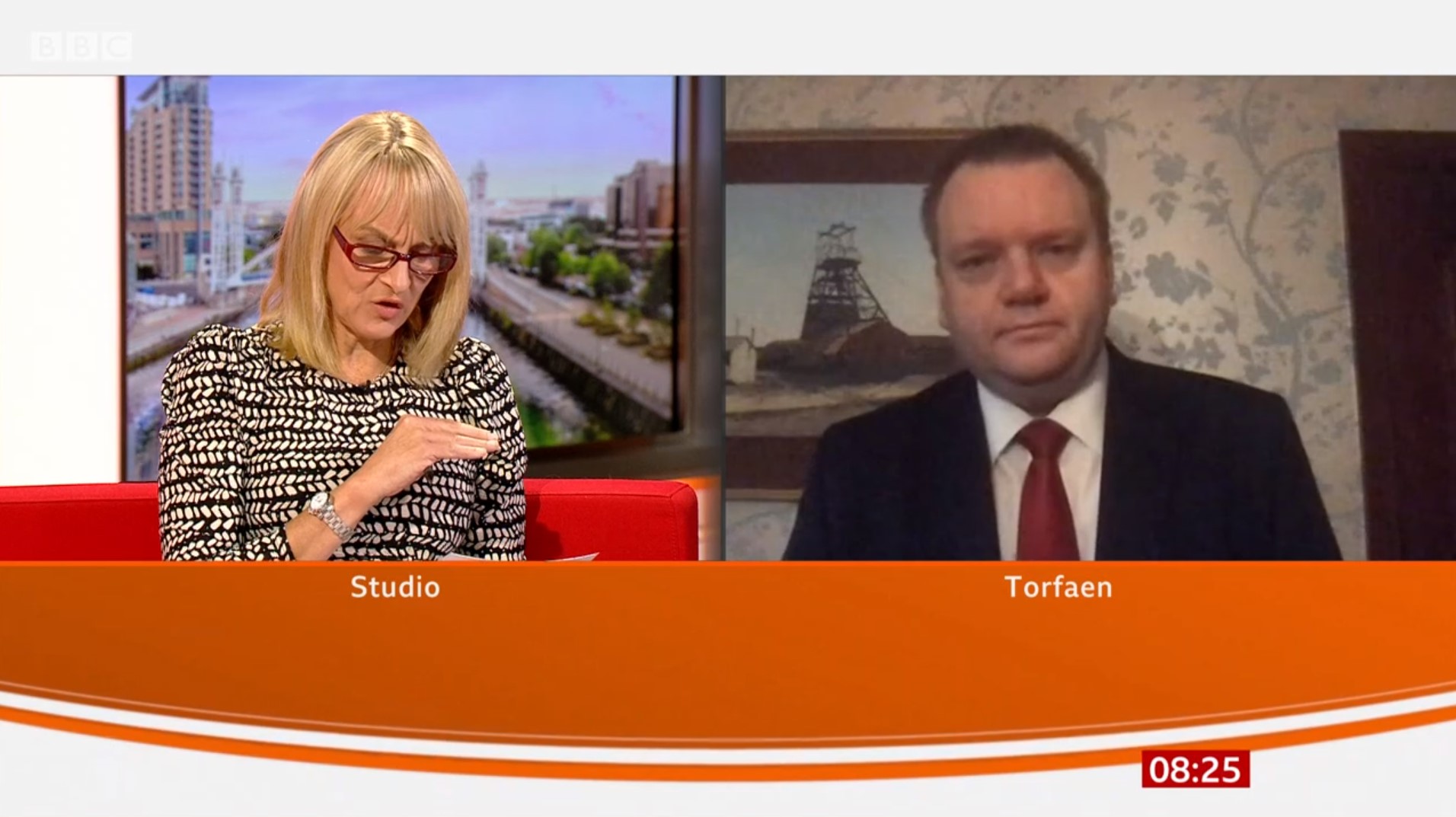
Four Months In – Many Politicians are Still ‘Zooming’ Badly
I posted a Twitter thread on this subject earlier, but I thought it was worth exploring a little more here. This morning I was watching BBC Breakfast, and Louise Minchen was interviewing Labour’s Shadow Home Secretary, Nick Thomas-Symonds from his home constituency in Torfaen. What I couldn’t get over was the poor resolution of Thomas-Symonds’…
-

Micropayments and Transaction Fees
Yesterday I wrote about my frustration that every news outlet that doesn’t want to – or more likely can’t – rely on advertising alone, wants to push me down a subscription route. I said that I am basically maxed out as far as news subscriptions go right now. I’d like a pay-as-you-go offering, much as…
-

USB-C: So Much User Uncertainty
The PC I’ve just been building (I’ll reveal all soon), has two USB-C sockets. The case at the front has a USB-C Gen 1 socket, matching the header on the motherboard, which allows 5 Gbps data transmission. The socket at the rear, is USB-C Gen 2, which doubles that to 10 Gbps. Neither of them…